
この記事ではwebスクレイピングで使う
requestsをインストールしていきます。
そのあと、実際にrequestsを使ってwebスクレイピングをやっていきましょう。
目次
【Python入門】requestsをインストールしてみよう
requestsをインストールする方法は簡単です。
まずanacondaをインストールしていることが前提になります。
なので、もしanacondaをインストールしていないようでしたら
こちらの記事を先にご覧ください。
⇒Anacondaをwindows7にインストールする方法
ではanacondaを開いてください。

Anaconda navigatorを開いたら
上記画像の赤枠にあるEnvironmentsをクリックしてください。
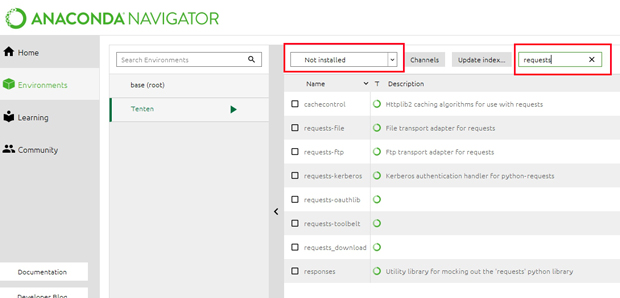
続いて上記画像赤枠内のように
Not Installedを選択し、『requests』と
入力してエンターを押してください。
もし、まだrequestsがインストールされていないなら
赤枠の下にrequestsが表示されます。
でも、表示されていないならインストールされています。
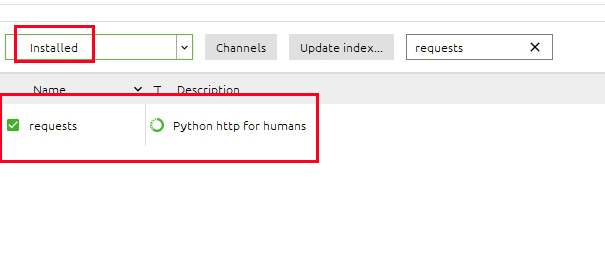
上記画像のように『Installed』を選択してみてください。
赤枠の下に『requests』が表示されたら
インストールされています。
で、もしNot installedに『requests』が表示されているなら

『requests』の左側にある□枠にチェックを入れてください。
すると、
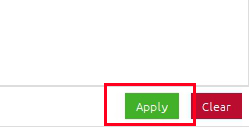
画面右下にApplyの枠が出るので
ここをクリックしてください。
そしたらインストールが始まります。
インストールが終了したら
となります。
これでrequestsのインストールが完了です。
では次にrequestsを使って
webスクレイピングをやっていきましょう。
【Python入門】requestsを使ってwebスクレイピングを実践する前に
Pythonだと、先ほどインストールしたrequestsのget()を利用することで
いとも簡単にホームページのHTMLを取得することができます。
今回は当サイト管理人が運営しているサイト
⇒http://hyogo-animalhospital.com/
のHTMLを取得してみたいと思います。
と、その前にまずホームページのHTMLを取得する(webスクレイピング)前の
注意点について解説します。
webスクレイピングを実行すると
HTMLを取得するホームページの利用規約であったり
アクセス制限のルールを守るようにお願いします。
また短時間に同じサイトにwebスクレイピングを行うと
サーバーにものすごい負荷をかけてしまいます。
腕立て伏せで腕を鍛えるのではなく
200㎏のバーベルで筋トレをするような負荷をかけるってことです。
そしたら、腕が壊れてしまいますね。
これと同じでwebスクレイピングのやりすぎで
サーバーに負荷をかけすぎてしまって
相手サイトを破壊してしまう危険性があるんです。
そうなったら、相手サイトの管理人やサーバー会社から
あなたに怖いメールが届く羽目になるかもしれません。
そうならないように、
実行間隔は最低でも10秒以上あけましょう。
それからあなたがこれからwebスクレイピングで得る情報には
著作権が存在する可能性が高いです。
法律に違反するような行為は絶対に控えてください。
よろしいでしょうか?
絶対に相手サイトの管理人やサーバー会社に迷惑をかけないこと、
具体的には実行間隔を最低でも10秒以上あけること、
それから、法律に違反する行為をしないこと
以上を必ず守ってください。
【Python入門】requestsを使ってwebスクレイピングを実践してみよう
それでは当サイト管理人が管理している別サイト
⇒http://hyogo-animalhospital.com/
のHTMLを取得してみたいと思います。
例題1をご覧ください。
#例題1 webスクレイピングをやってみよう
import requests
request = requests.get("http://hyogo-animalhospital.com/")
print(request.text)
実行すると、以下のように
HTML情報を取得することができます。
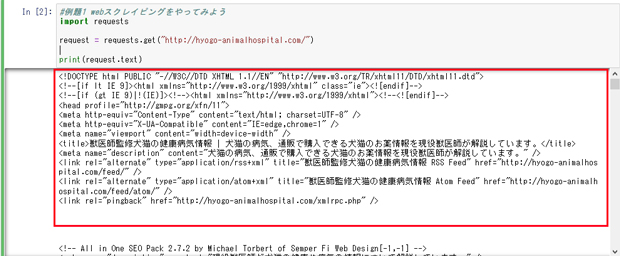
例題1について解説していきますね。
まず、
import requests
HTML情報の取得に必要なrequestsモジュールを
インポートしています。
それから
request = requests.get("http://hyogo-animalhospital.com/")
requestsのget関数を使って当サイト管理人のサイトにあるHTML情報を取得します。
そして
print(request.text)
と記述することで、得られたHTMLを表示させているわけです。
今回の解説は以上になります。
今後、beautifulsoupについても解説していきますので
よろしくお願いします。
pythonを学ぶならこちらの動画講座がおすすめです
Python 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイルを学び、実践的なアプリ開発の準備をする
かなり長い講座名ですね。
わかりにくそうな感じがします。ですが、pythonの基礎からしっかりとわかりやすく教えてくれます。
また、きれいなコードを書くための方法についても
教えてくれるので、周りが「どうやってそんなコードを書いてるの?」
とびっくりされるようになるかもしれません。それからWebアプリケーション開発の基本的なテクニックについても
教えてくれます。なので、pythonを使ってwebアプリケーションを作ってみようと
思っている方にもおすすめです。値段は時期によって違います。
詳しくはこちらをご覧ください。
みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習
この講座ではまずpythonの基礎を学びます。
次に人工知能について学んでいきます。そして最終的にはpythonを使って文字認識や株価分析ができるような技術力が身につくようになっています。
単純に教科書的なpythonを学ぶのではなく
仕事でも使えるスキルを身につけたい方におすすめの講座です。なのに値段は恐ろしいほど安いです。
時期によって値段は変動するので
詳しくはこちらをご覧ください。
Pythonで機械学習:scikit-learnで学ぶ識別入門
この動画講座は広島大学准教授の先生が担当しています。
機械学習が専門の先生です。すごく深い知識が身につきます。
大学の先生の講義って難しそうってイメージがあるかもしれません。でもそんなことはありません。
すごくわかりやすいです。pythonで機械学習のスキルを身につけたい方におすすめです。
値段は時期によって違いますが、かなり、良心的な価格になっています。詳しくはこちらをご覧ください。






