- 2018-9-13
- スクレイピング
- beautifulsoup, python, インストール, 使い方
- 【Python】beautifulsoupのインストール方法と使い方 はコメントを受け付けていません

前回の記事ではPythonでwebスクレイピングするのに必須の
requestsをインストールする方法について解説しました。
あとついでに、実際に管理人の別サイトのHTML情報を取得してみました。
まだご覧になっていない方はこちらからどうぞ。
⇒requestsをインストールしてPythonでwebスクレイピングしてみた
webスクレイピングはrequests以外にも
beautifulsoupがあります。
もちろんrequestsとbeautifulsoupは違います。
この記事ではbeautifulsoupのインストール方法について解説し
そのあとで、使い方について解説していきます。
【Pythom】beautifulsoupをインストールしてみよう
beautifulsoupをインストールしていきましょう。
まずanacondaをインストールしていることが前提になります。
なので、もしanaconda navigatorをインストールしていないようでしたら
こちらの記事を先にご覧ください。
⇒Anacondaをwindows7にインストールする方法
ではanaconda navigatorを開いてください。

anaconda navigatorを開いたら
Environmentsをクリックしてください。
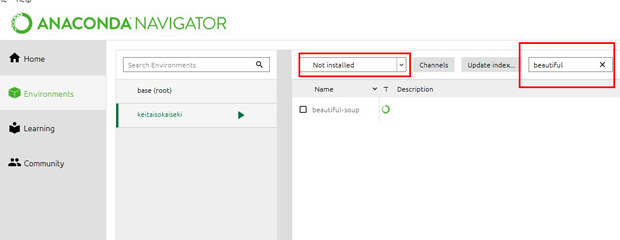
次にNot installedを選択して
『beautiful』と入力してみてください。
すると、画面下あたりに『beautifulsoup4』と出るかと思います。
もし出ないならNot installedをInstalledに切り替えてください。
もしInstalledの下にbeautifulsoup4があるなら
すでにインストールはすんでいます。
Not installedにあるなら
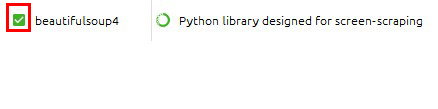
左端のチェックを入れて
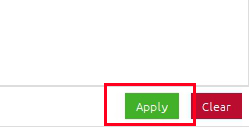
Applyをクリックしてください。
これでインストールが始まります。
インストールが終わったら
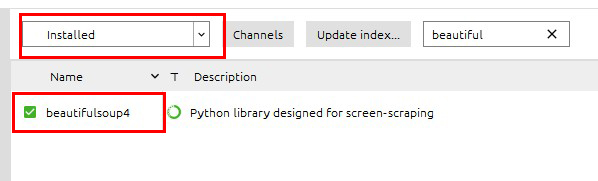
Installedにしてみてください。
その下にbeatifulsoup4があれば、インストールが成功しています。
これでbeautifulsoupのインストールは完了しました。
次に実際にbeautifulsoupを使っていきましょう。
【Pythom】beautifulsoupの使い方
管理人のサイトの個別記事から必要な情報だけを抜き出してみましょう。
まず
#例題1
import requests
request = requests.get("http://hyogo-animalhospital.com/%e7%8a%ac%e3%81%ab%e9%96%a2%e3%81%99%e3%82%8b%e8%a8%98%e4%ba%8b/%e7%8a%ac%e4%bd%95%e7%a8%ae%e6%b7%b7%e5%90%88%e3%83%af%e3%82%af%e3%83%81%e3%83%b3/")
print(request.text)
例題1では管理人の個別ページのHTML情報を抜き出しました。
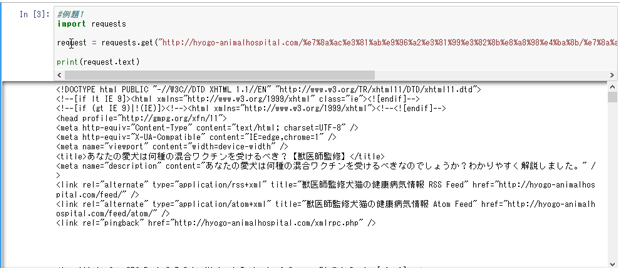
では上記抜き出したhtmlの中で
最初のpタグだけ抜き出してみましょう。
#例題2
import requests
from bs4 import BeautifulSoup
aaa = requests.get("http://hyogo-animalhospital.com/%e7%8a%ac%e3%81%ab%e9%96%a2%e3%81%99%e3%82%8b%e8%a8%98%e4%ba%8b/%e7%8a%ac%e4%bd%95%e7%a8%ae%e6%b7%b7%e5%90%88%e3%83%af%e3%82%af%e3%83%81%e3%83%b3/")
soup = BeautifulSoup(aaa.text)
print(soup.find("p"))
例題2で以下は狙ったURLを指定す以外、定型文です。
import requests
from bs4 import BeautifulSoup
aaa = requests.get("http://hyogo-animalhospital.com/%e7%8a%ac%e3%81%ab%e9%96%a2%e3%81%99%e3%82%8b%e8%a8%98%e4%ba%8b/%e7%8a%ac%e4%bd%95%e7%a8%ae%e6%b7%b7%e5%90%88%e3%83%af%e3%82%af%e3%83%81%e3%83%b3/")
soup = BeautifulSoup(aaa.text)
で、
print(soup.find("p"))
によって、最初のpタグ内だけが取得できます。
実際に実行してみると
愛犬に混合ワクチンを受けさせたいと思った時に
悩むことがあると思います。
と表示されます。
pタグで記述されているところを全部抜き出したいときは
#例題3
import requests
from bs4 import BeautifulSoup
aaa = requests.get("http://hyogo-animalhospital.com/%e7%8a%ac%e3%81%ab%e9%96%a2%e3%81%99%e3%82%8b%e8%a8%98%e4%ba%8b/%e7%8a%ac%e4%bd%95%e7%a8%ae%e6%b7%b7%e5%90%88%e3%83%af%e3%82%af%e3%83%81%e3%83%b3/")
soup = BeautifulSoup(aaa.text)
print(soup.find_all("p"))
と、find_allと記述することで実現できます。
idを抜き出すこともできますよ。
#例題4
import requests
from bs4 import BeautifulSoup
aaa = requests.get("http://hyogo-animalhospital.com/%e7%8a%ac%e3%81%ab%e9%96%a2%e3%81%99%e3%82%8b%e8%a8%98%e4%ba%8b/%e7%8a%ac%e4%bd%95%e7%a8%ae%e6%b7%b7%e5%90%88%e3%83%af%e3%82%af%e3%83%81%e3%83%b3/")
soup = BeautifulSoup(aaa.text)
print(soup.find_all(id="i-2"))
実行すると
[愛犬に何種の混合ワクチンを受けさせるべき?]
と表示されますが、
これは元のhtmlでは
<h3><span id="i-2">愛犬に何種の混合ワクチンを受けさせるべき?</span></h3>
となっているところを抜き出しています。
こんな感じでrequestsだとhtml全体を抜き出すのに対して
beautifulsoupだと狙った箇所だけ抜き出すことができます。
以上で解説を終わります。
pythonを学ぶならこちらの動画講座がおすすめです
Python 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイルを学び、実践的なアプリ開発の準備をする
かなり長い講座名ですね。
わかりにくそうな感じがします。ですが、pythonの基礎からしっかりとわかりやすく教えてくれます。
また、きれいなコードを書くための方法についても
教えてくれるので、周りが「どうやってそんなコードを書いてるの?」
とびっくりされるようになるかもしれません。それからWebアプリケーション開発の基本的なテクニックについても
教えてくれます。なので、pythonを使ってwebアプリケーションを作ってみようと
思っている方にもおすすめです。値段は時期によって違います。
詳しくはこちらをご覧ください。
みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習
この講座ではまずpythonの基礎を学びます。
次に人工知能について学んでいきます。そして最終的にはpythonを使って文字認識や株価分析ができるような技術力が身につくようになっています。
単純に教科書的なpythonを学ぶのではなく
仕事でも使えるスキルを身につけたい方におすすめの講座です。なのに値段は恐ろしいほど安いです。
時期によって値段は変動するので
詳しくはこちらをご覧ください。
Pythonで機械学習:scikit-learnで学ぶ識別入門
この動画講座は広島大学准教授の先生が担当しています。
機械学習が専門の先生です。すごく深い知識が身につきます。
大学の先生の講義って難しそうってイメージがあるかもしれません。でもそんなことはありません。
すごくわかりやすいです。pythonで機械学習のスキルを身につけたい方におすすめです。
値段は時期によって違いますが、かなり、良心的な価格になっています。詳しくはこちらをご覧ください。






